
Claude AI Transformations in Document Analysis: Driving Efficient, Accurate Processing
Claude AI transforms document analysis by applying large language models, embeddings, and contextual retrieval to automate summarization, extraction, and classification while improving accuracy and reducing manual review. This article explains how those mechanisms work, the specific capabilities that drive change, and practical steps for deploying Claude AI in real workflows. The content is published as an Information Hub, Lead Generation, Service Provision resource to help technical and business audiences evaluate document analysis with Claude. Readers will learn how Claude AI document analysis differs from legacy pipelines, what features to expect, and how to design summarization-to-routing workflows that preserve governance and privacy. The following sections unpack core capabilities, list practical features, show optimized workflow patterns, and close with benefits and deployment considerations for teams evaluating Claude AI document processing.
How does Claude AI transform document analysis and processing for organizations?
Claude AI transforms document analysis by shifting the core task from brittle rule-based parsing to probabilistic, context-aware understanding powered by LLMs and embeddings. This approach enables the system to interpret intent, extract entities, and produce concise summaries directly from raw text, which reduces human triage and accelerates decision cycles. The transformation is measurable through improved throughput, fewer manual touchpoints, and more consistent classifications across heterogeneous document types. Understanding the capabilities that make this possible clarifies why many teams consider document analysis with Claude when modernizing workflows.
Further insights into the underlying large language model architectures and their performance characteristics can be found in recent research.
Claude AI in the LLM Landscape: Architectures & Performance
This survey provides a comprehensive review of major proprietary and open-source LLM families, including GPT, LLaMA 2, Gemini, Claude, DeepSeek, Falcon, and Qwen. It systematically examines architectural advancements such as transformer refinements, mixture-of-experts paradigms, attention optimization, long-context modeling, and multimodal integration. The paper further analyzes alignment and safety mechanisms, encompassing instruction tuning, reinforcement learning from human feedback, and constitutional frameworks, and discusses their implications for controllability, reliability, and responsible deployment.Mapping the LLM Landscape: A Cross-Family Survey of Architectures, Alignment Methods, and
Benchmark Performance, D Bhati, 2026
What core capabilities drive the transformation?
Core capabilities include robust document summarization, precise text extraction, adaptive classification, and contextual retrieval via embeddings. Summarization condenses long documents into actionable highlights, extraction isolates structured facts and key-value pairs, and classification maps content to taxonomies for downstream routing. These capabilities rely on LLM-based understanding rather than brittle pattern matching, making them resilient across formats and industries. Together they enable a pipeline that prioritizes insights and reduces repetitive human review, which leads naturally into how those gains translate to speed and accuracy.
How does Claude AI improve speed and accuracy versus traditional tools?
Claude AI improves speed by automating the steps that traditionally required manual review or complex regex/OCR post-processing, shortening time-to-insight from hours to minutes for many document types. Accuracy improves because contextual models reduce false positives and negatives by using semantics rather than surface patterns to interpret content. Human-in-the-loop checkpoints remain practical and targeted, which preserves quality while lowering review volume. These improvements make Claude summarization and classification preferable where documents are diverse, context-rich, or where scaling manual processes would be costly.
What document processing capabilities does Claude AI provide?

Claude AI document processing provides a set of integrated features: abstractive and extractive summarization, structured text extraction for tables and key-value pairs, taxonomy-driven classification, metadata tagging, and automated routing to workflows. The system supports mixed formats and can be configured to return different output shapes depending on downstream needs, which eases integration with search, RAG (retrieval-augmented generation), and analytics layers. Below is a compact comparison of capabilities, typical outputs, and ideal inputs to guide system selection and pipeline design.
Different processing capabilities, their typical outputs, and recommended inputs are summarized here.
This table clarifies what each capability yields and which document types make the most sense for each approach. The next subsections explore integration of summarization and extraction and then classification and workflow organization.
Integrated summarization and text extraction features
Integrated summarization and text extraction combine abstractive condensation with precise data capture, so a single pipeline can produce both an executive summary and machine-readable fields. Configuration options let teams choose extractive outputs for compliance fields and abstractive summaries for decision briefs, balancing fidelity and readability. Supported input types commonly include PDFs, plain text, OCRed images, and structured tables; outputs are JSON, CSV, or plain text depending on downstream consumers. When designing pipelines, use extractive methods for regulatory data and abstractive methods for quick insights, which informs classification and routing choices in the next section.
The effectiveness of LLMs in automating precise data extraction, particularly from complex documents like scientific literature, is further supported by recent studies.
LLM-Powered Automated Data Extraction for Scientific Literature
We present Data Gatherer, an automated system that leverages large language models to identify and extract dataset references from scientific publications. To evaluate our approach, we developed and curated two high-quality benchmark datasets specifically designed for dataset identification tasks. Our experimental evaluation demonstrates that Data Gatherer achieves high precision and recall in automated dataset reference extraction, reducing the time and effort required for dataset discovery while improving the systematic identification of data sources in scholarly literature.
Data gatherer: LLM-powered dataset reference extraction from scientific literature, P Marini, 2025
Classification and workflow organization for documents
Classification maps documents to taxonomies, enabling automated routing, tagging, and downstream processing. Teams create hierarchical taxonomies, train or fine-tune classifiers on labeled examples, and define routing rules that trigger actions like human review, archival, or escalation. Governance requirements suggest maintaining audit logs and explainability metadata for each classification decision to support compliance and troubleshooting. Clear taxonomies and governance controls keep automated workflows auditable while maximizing the benefits of automated document classification.
How does Claude AI optimize summarization, extraction, and classification workflows?
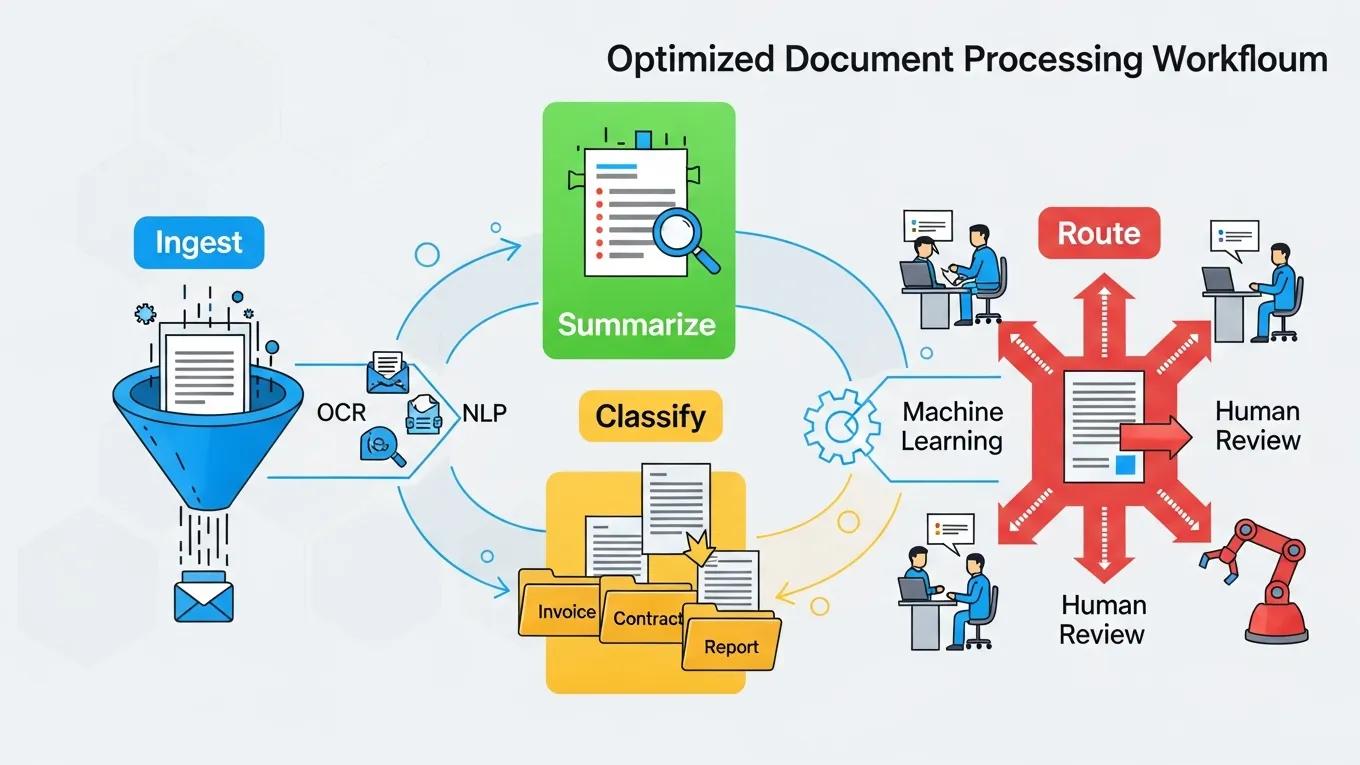
Claude AI optimizes workflows by orchestrating ingest, parallel processing, validation, and routing while exposing checkpoints for monitoring and human review. Orchestration patterns include batching for throughput, streaming for low-latency needs, and hybrid modes that combine both depending on document velocity. Automation points reduce manual effort at extraction and tagging, while guardrails enforce quality through validation and sampling. These patterns let teams scale document analysis while preserving safety and governance expectations.
This table illustrates how orchestration and automation reduce manual effort and improve consistent outcomes. The following H3s give concrete patterns for summarization flows and governance-enabled routing.
Summarization workflows and key insight extraction
An effective summarization workflow follows ingest → preprocess → summarize → validate → store, with checkpoints at validation for human review when confidence is low. Key insight extraction uses named-entity recognition and timeline detection to surface facts, dates, and obligations that matter for decisions. Validation rules compare extracted facts to source segments and flag discrepancies for human triage to maintain accuracy. These steps produce concise decision artifacts while preserving traceability to original documents, which supports governance and auditing needs discussed next.
Automated routing, tagging, and governance
Automated routing applies classification outputs and confidence thresholds to tag and route documents to queues or systems for action, reducing manual triage. Tag taxonomies should include risk, priority, and business unit dimensions to ensure precise handling; rules can escalate high-risk items or send ambiguous cases to reviewers. Governance is enforced through role-based access controls, immutable audit logs, and policy checkpoints that require approvals for sensitive document flows. Proper governance aligns throughput gains with compliance and safety responsibilities, leading into practical benefits and deployment steps.
What are the practical benefits and implementation considerations for Claude AI in document analysis?
Practical benefits include measurable time savings, more consistent decision support, and reduced error rates compared with manual pipelines. Time savings manifest as fewer reviewer hours per document and faster cycles from receipt to action. Decision support improves because concise summaries and extracted facts reduce cognitive load and surface actionable items quickly. These operational gains make Claude AI document processing attractive for operations, legal, research, and customer service teams looking to scale document workloads.
Real-world benefits: time savings, decision support, and accuracy improvements
Organizations often see quicker turnaround for routine document tasks, such as triage and compliance checks, when replacing manual review with automated summarization and extraction. Decision-makers receive concise briefs and structured facts that improve the speed and quality of choices, while consistency improves because model-driven extraction reduces human variability. Measurement approaches include tracking reviewer hours, error rates in extracted fields, and time-to-decision metrics to quantify ROI. Together, these benefits justify pilot programs and scaling plans that prioritize high-volume or high-value document types.
Deployment considerations: data privacy, integration with existing systems, and governance
Deployment requires planning for data privacy (encryption, residency, access controls), integration patterns (API, SDKs, webhook orchestration), and governance (audit trails, explainability, testing). Teams should pilot with limited document sets, validate extraction accuracy, and iterate taxonomy and validation rules before scaling. For developers and businesses evaluating integration options, Claude API document processing capabilities and associated research and safety resources support secure, maintainable deployments without sacrificing model performance. Careful rollout, continuous monitoring, and governance checkpoints ensure operational reliability and compliance during scale-up.
Claude AI offers an approach to modernize document processing workflows, combining semantic understanding with configurable pipelines, and delivering faster, more accurate outcomes while preserving governance and privacy controls.